3D scene generation is in high demand across various domains, including virtual reality, gaming, and the film industry.
Owing to the powerful generative capabilities of text-to-image diffusion models that provide reliable priors, the creation of 3D scenes using only text prompts has become viable, thereby significantly advancing researches in text-driven 3D scene generation.
In order to obtain multiple-view supervision from 2D diffusion models, prevailing methods typically employ the diffusion model to generate an initial local image, followed by iteratively outpainting the local image using diffusion models to gradually generate scenes. Nevertheless, these outpainting-based approaches prone to produce global inconsistent scene generation results without high degree of completeness, restricting their broader applications.
To tackle these problems, we introduce HoloDreamer, a framework that first generates high-definition panorama as a holistic initialization of the full 3D scene, then leverage 3D Gaussian Splatting (3D-GS) to quickly reconstruct the 3D scene, thereby facilitating the creation of view-consistent and fully enclosed 3D scenes.
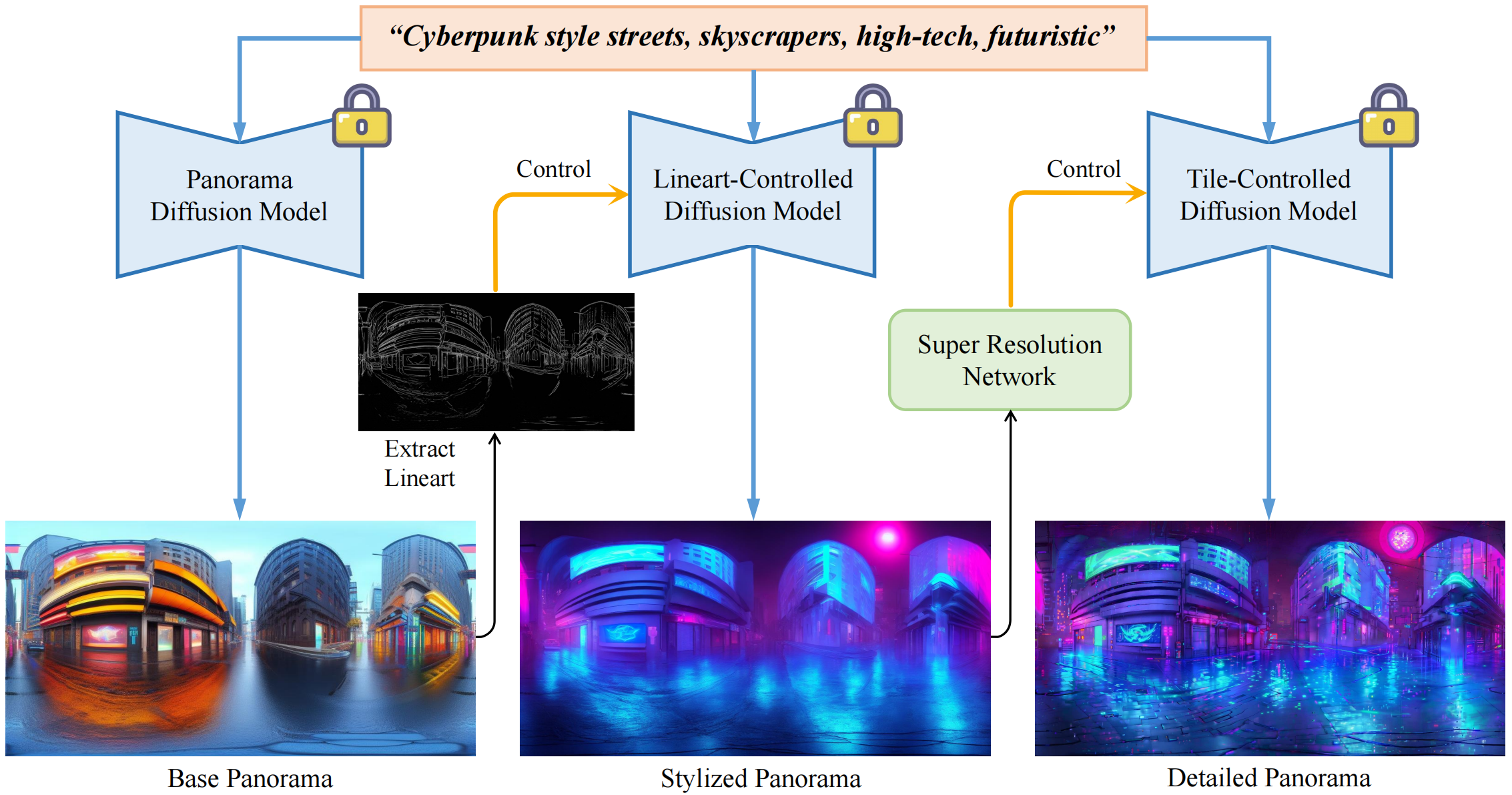
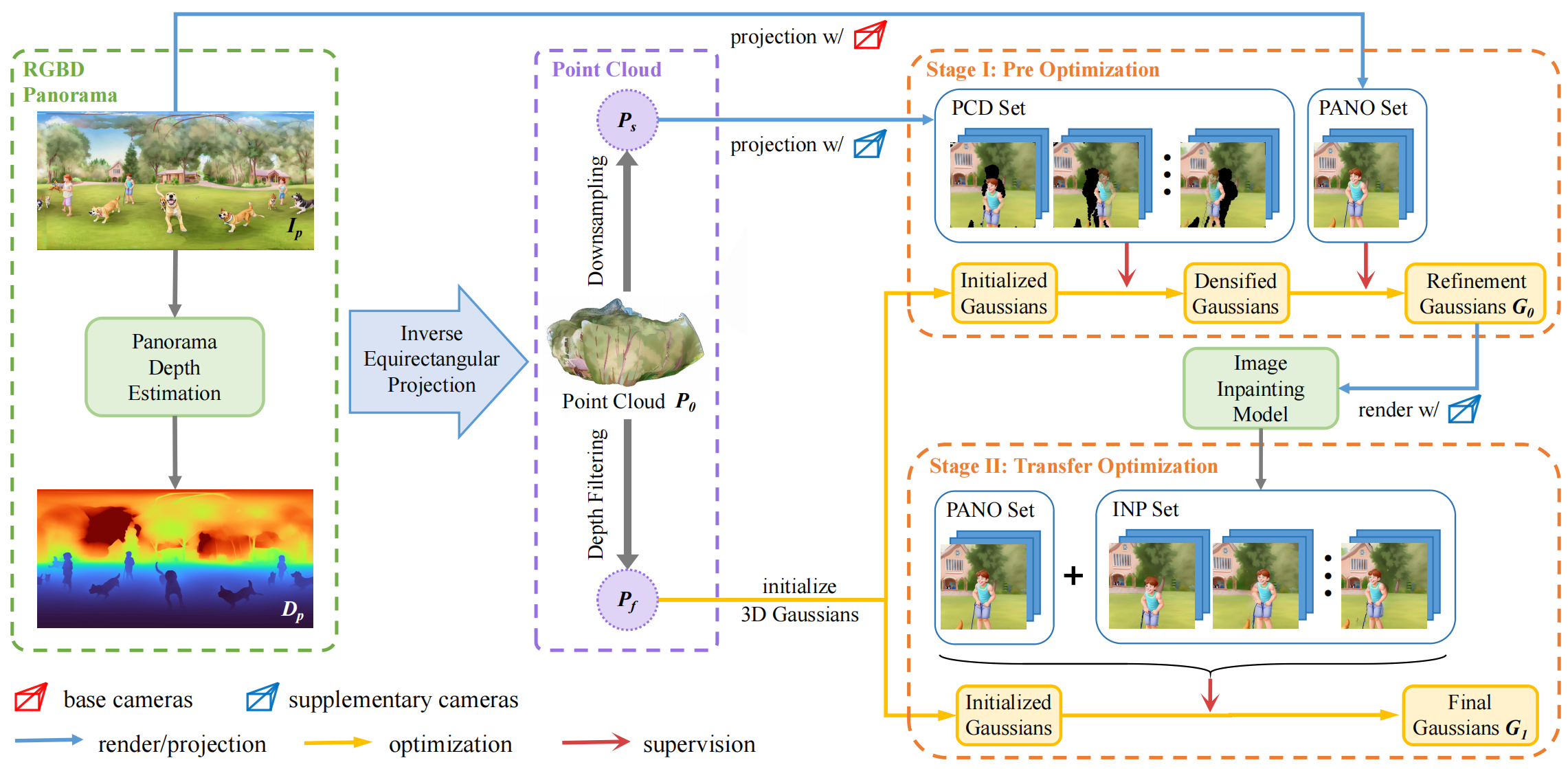
Specifically, we propose Stylized Equirectangular Panorama Generation, a pipeline that combines multiple diffusion models to enable stylized and detailed equirectangular panorama generation from complex text prompts. Subsequently, Enhanced Two-Stage Panorama Reconstruction is introduced, conducting a two-stage optimization of 3D-GS to inpaint the missing region and enhance the integrity of the scene. Comprehensive experiments demonstrated that our method outperforms prior works in terms of overall visual consistency and harmony as well as reconstruction quality and rendering robustness when
generating fully enclosed scenes.